For my Master’s thesis, I applied Quality Diversity principles to create an end-to-end pipeline for procedural racing track generation and evaluation. The system used the MAP-Elites genetic algorithm and introduced a novel representation based on Voronoi diagrams.
The Lore
Video game development requires enormous resources for content creation—especially for core assets like levels and tracks.
Designing a hundred different, fun, and high-quality racing tracks is a major challenge.
Traditional procedural content generation (PCG) often produces bland, repetitive results, because most optimization algorithms are built to find a single “best” solution.
Quality Diversity (QD) algorithms flip this logic: they aim to produce an archive of high-quality but fundamentally distinct solutions.
In this work, I applied QD to the procedural generation of racing tracks. While the open-source simulator TORCS was the workhorse for evaluation, the pipeline’s fundamental output isn’t a TORCS-specific file—it’s a universal track layout defined by a spline. This makes the generated content engine-agnostic and ready to be used in any modern game engine or software.
All You Need Is Diversity
Procedural content generation automatically creates assets through algorithms, reducing design effort while increasing variety.
The key challenge: how to generate content that is both high-performing and diverse.
Traditional optimization looks for one solution. QD methods search for many solutions that are:
- High-Quality (performant, challenging)
- Diverse (different in meaningful ways)
To achieve this, I used the MAP-Elites (Multi-dimensional Archive of Phenotypic Elites) algorithm to illuminate the design space and create diverse track layouts.
MAP-Elites: Illuminating the Feature Space
Most optimizers chase a single peak and can get stuck.
MAP-Elites works by:
- Dividing the space of possible designs into a grid (an “archive”).
- Storing the best-performing solution per cell.
- Producing not one solution, but a map of diverse, high-quality “elites.”
Why it works:
- It’s robust to deception and local optima by exploring many regions in parallel.
- Diversity pays compounding dividends: seemingly average paths can uncover breakthroughs a single‑objective search never sees.
MAP‑Elites can search the space of all possible robot designs (a very high‑dimensional space) and find the fastest robot (performance) for each combination of height and weight (behavior). Same idea here: for tracks, the grid is defined by learned geometric/telemetry descriptors, and each cell stores the current best‑performing layout with those characteristics.
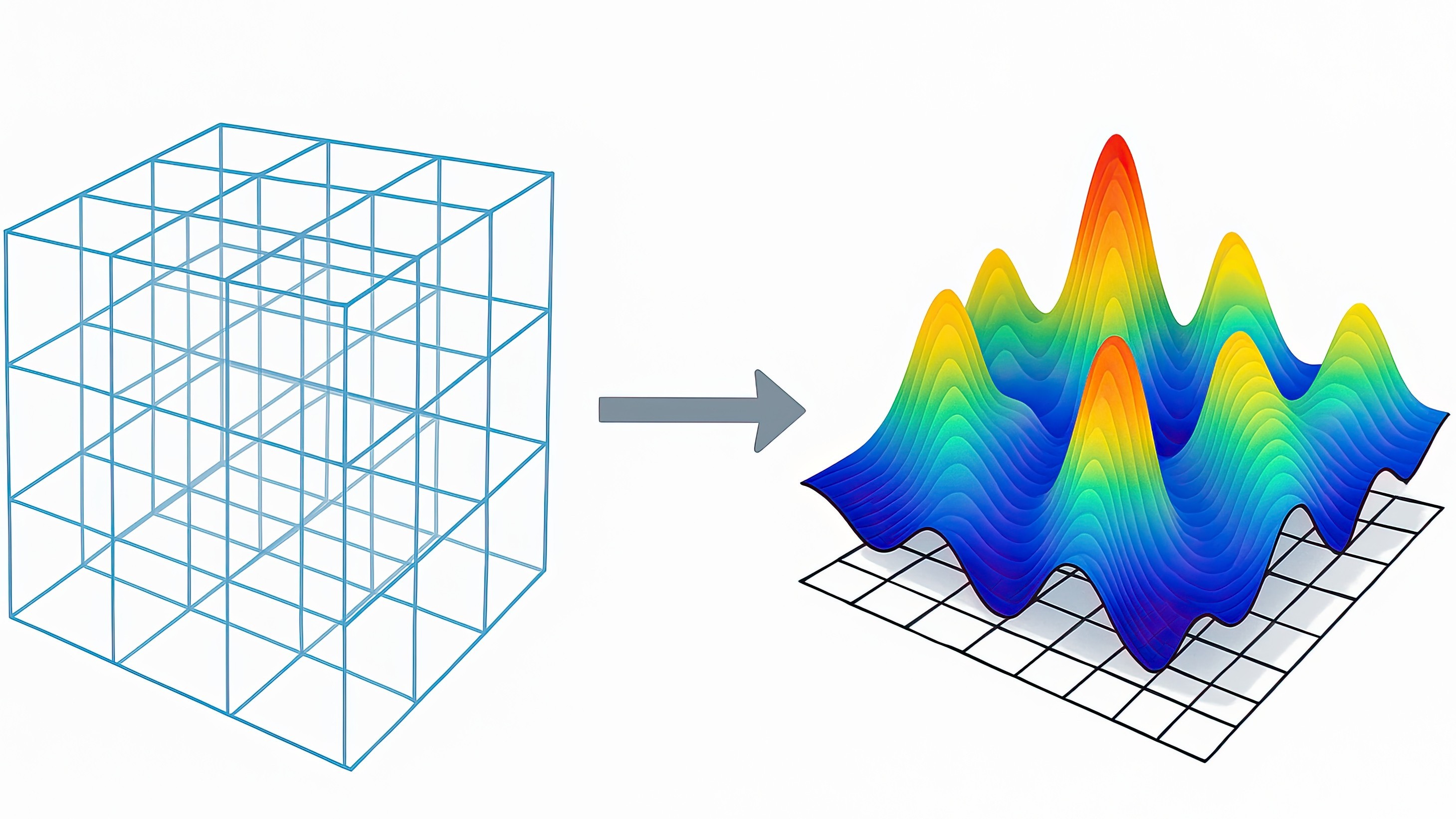
Net result: instead of guessing the summit, you illuminate the whole landscape. For procedural generation, that means not just strong tracks, but an atlas of high‑quality, meaningfully different ones—useful for both discovery and selection. We then evaluated tracks by simulating AI-driven races and analyzing telemetry.
The Pipeline
Tracks were simulated with The Open Racing Car Simulator (TORCS)—an open-source platform with realistic physics, modular AI drivers, and a useful headless mode for large-scale experiments.
However, TORCS is outdated and limited (e.g., no altitude changes). For future work, a modern engine such as Unity or Unreal would be more flexible, enabling 3D track features like elevation and banking.
The overall system included:
- Python & Pyribs for running MAP-Elites and handling data analysis in Jupyter Notebooks.
- Node.js backend for track generation and a custom HTTP API.
- p5.js web frontend for real-time visualization of generated tracks.
- Dockerized TORCS simulations with custom telemetry modules, allowing scalable, fault-tolerant parallel execution.
Through experiments, I found basic gameplay metrics to be noisy. For example, raw overtakes were unstable due to geometry artifacts. I introduced normalized measures (e.g., overtakes corrected by geometric closure error) to make evaluation more robust.
We also derived track descriptors from both geometry (length, turns) and gameplay signals (entropy of curvature or speed), then applied UMAP dimensionality reduction to define a reliable behavioral space guiding the QD search.
Track DNA – From Genotype to Phenotype
We evolved genotypes (compact numeric arrays) that were deterministically decoded into phenotypes (concrete track layouts).
Representation methods included:
Convex Hulls: seed points define a polygonal boundary, smoothed into a track. Predictable but somewhat constrained.

Voronoi Diagrams (novel method): tracks emerge from the edges of Voronoi tessellations. Selecting subsets of cells produced continuous closed-loops—more expressive and organic than convex hulls.

Beyond simple mutation (shifting seed points), I designed custom crossover operators for Voronoi genotypes, including methods like Random-Line Partitioning and Relative Reconstruction, which enabled parent tracks to blend effectively.
Illuminating Multidimensional Racing 🏎️
Instead of hand-defining features like “number of turns,” we let the data itself define diversity. This is where UMAP comes in. UMAP (Uniform Manifold Approximation and Projection) is a dimensionality reduction algorithm designed to distill from an high-dimensional data a simple underlying manifold structure. It builds a nearest-neighbor graph in the original high-dimensional space and then optimizes a low-dimensional embedding that preserves those neighborhood relationships. Unlike older methods like t-SNE, it’s generally faster and better at keeping both local and global structure intact.
We then used the UMAP space to guide search:
- Sample each track’s spline into a fixed-length vector.
- Make these splines centered (in their coordinates) and rotation-invariant.
- Use UMAP to project these vectors into 2D behavioral descriptors. This creates a map where proximity means geometric similarity.
- Run MAP-Elites on this learned space, so each cell in the archive represents a coherent niche of track geometry.
This approach replaces brittle, hand-picked features with a robust, data-driven manifold. The resulting archive is also more interpretable—clusters often map to recognizable track “styles,” while empty regions can indicate flawed or unfeasible designs (the big empty space at the center of the plot).
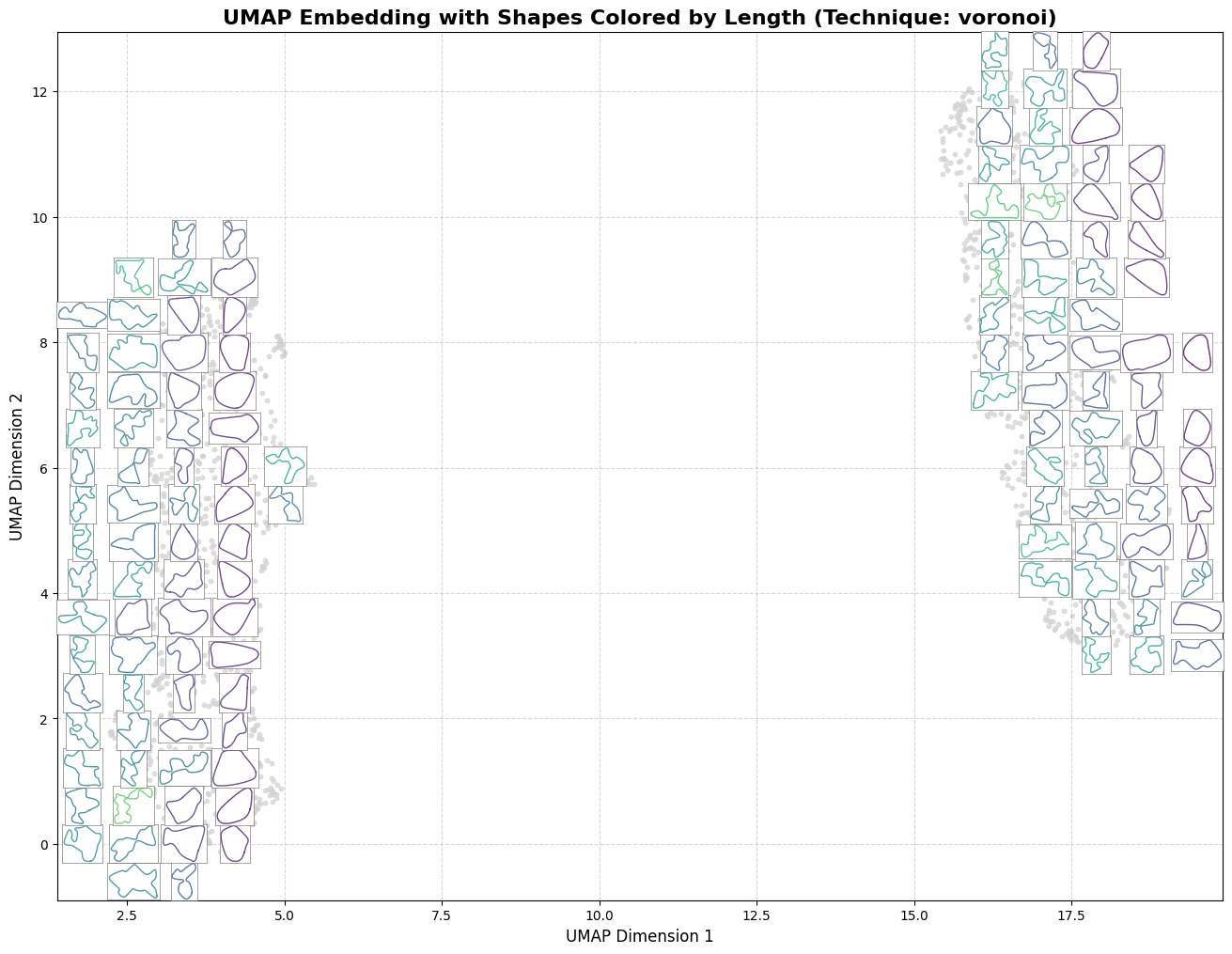 It effectively turns the search from guessing a single summit into illuminating the entire landscape of high-quality possibilities.
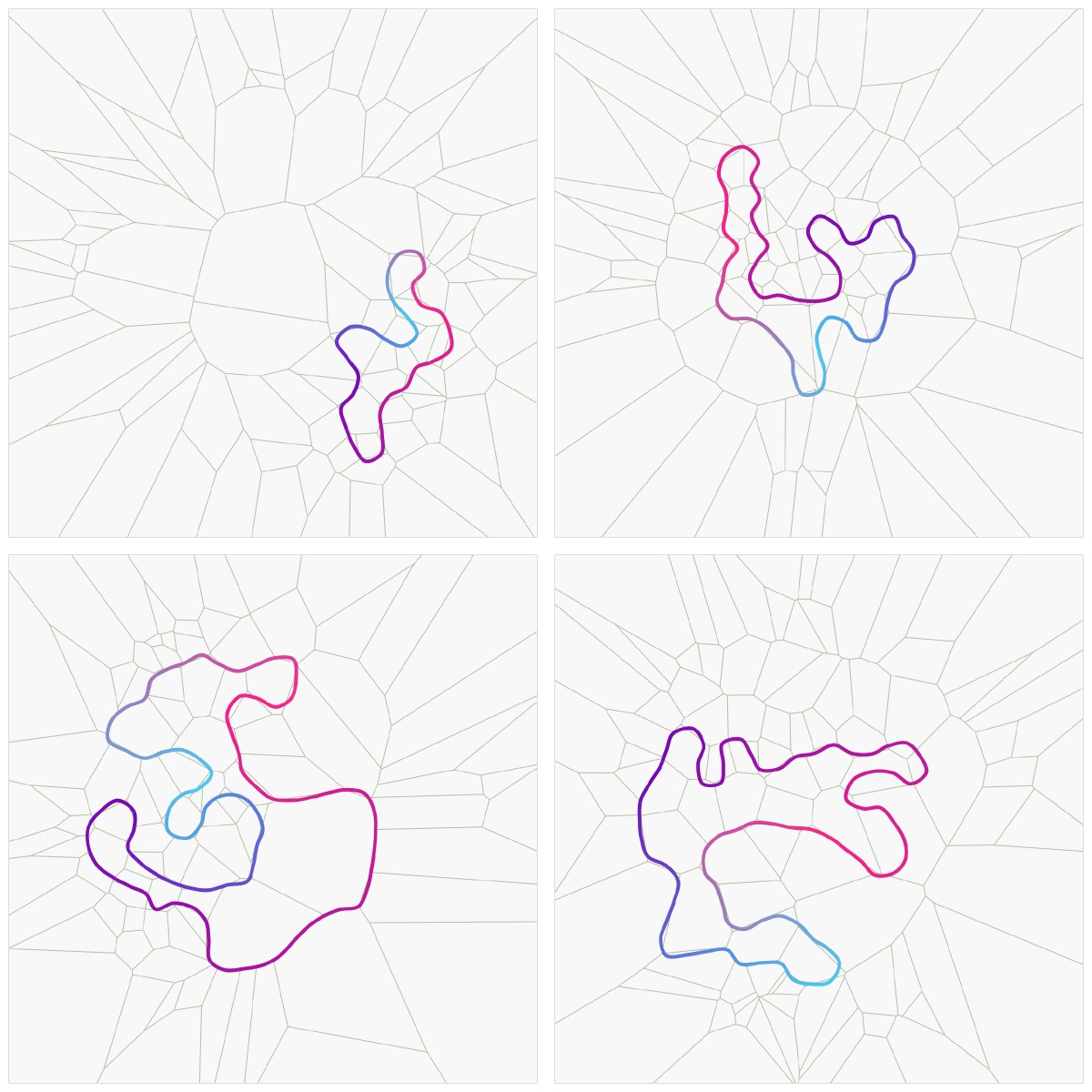
This is a sample of 4 random tracks in an experiment where they are maximized the curvature entropy and the total overtakes:
It effectively turns the search from guessing a single summit into illuminating the entire landscape of high-quality possibilities.
This is a sample of 4 random tracks in an experiment where they are maximized the curvature entropy and the total overtakes:
Lessons Learned
- Interactive visualization wasn’t optional, it was critical. Real‑time views made debugging geometry and understanding how operators behaved dramatically faster and more reliable.
- Orchestrating everything behind a backend paid off. Containerized sims add overhead (one sim per container), but the fault isolation and easy parallelism were worth it.
- TORCS is open, hackable, and got the job done—but it’s dated. Migrating to a modern engine (Unity/Unreal) is the obvious next step, not least to support elevation, banking, and richer geometry that TORCS simply can’t represent.
- Maybe introduce surrogate models to predict track quality and reduce costly simulations (?)
- Put a human in the loop. For inherently subjective targets (fun, flow, aesthetics) → designer feedback can steer the search where metrics can’t.
- My MAP‑Elites implementation was simple. There’s headroom in newer QD methods (e.g., gradient‑assisted variants like DCG‑MAP‑Elites) to explore the space more efficiently.
Extra
Note: this post is deliberately oversimplified. I’ve skipped a lot of engineering details, dead ends, and TORCS quirks, as well as the messier parts of building the “framework” around generation, evaluation, and orchestration. The full methodology, design decisions, and trade‑offs are documented in the thesis—see the Methodology chapter for the complete story.
The full source code, visualization tool, and thesis are available here:
While researching for the kickoff of this thesis, I found this interesting talk on open‑ended processes:
It explores what comes after you’ve filled an archive with diverse solutions: open-ended processes. These are systems with no final objective that just keep inventing new possibilities by building on what they’ve already found. It’s the same brand of never-ending creativity that generated all of biological diversity, and it points toward more ambitious AI goals. For anyone into procedural gen, this feels like a natural extension of QD and where the really fascinating problems are.